Számos ügyfélnél merül fel a kérdés, hogy az egyre csak növekvő SAP HANA adatbázisuk méretét hogyan tudják kordában tartani és költséghatékonyan bővíteni. Mivel egy memória alapú adatbázisról beszélünk, így nagyon nem mindegy, hogy mennyi memóriát szükséges allokálni az adatbázis számára, és milyen lehetőségek vannak az adatbázis memórián kívül való tárolására (virtualizációban is úgynevezett “reservation”-t kell beállítani ezzel csökkentve a konszolidáció mértékét).
Az idő múlásával a régebbi adatok relevanciája, értéke csökken, és kevéssé gyakran használjuk őket. Ha így közelítjük meg, akkor az, hogy egy adatbázis minden tábláját memóriában tároljuk nem a legköltséghatékonyabb megoldás. Éppen ezért az SAP egy olyan öltettel állt elő, aminek segítségével a ritkábban használt adatokat a memóriából egy alacsonyabb rétegbe mozgathatjuk, például egy tárolóra. Mivel a disk kapacitás per-Gigabyte alapon olcsóbb, mint a memória, így könnyen belátható, hogy ezzel költséghatékonyabbá tehető az SAP HANA rendszert kiszolgáló infrastruktúra.
Na, de lássuk, hogyan is működik az SAP Data Tiering megoldása nagyvonalakban.
Aki egy kicsit is jártas a tárolók világában, már találkozhatott „tiering” megoldással, aminek lényege, hogy több rétegen tároljuk az adatainkat annak megfelelően, hogy mennyire gyakran használjuk őket. Ezek között pedig egy valamilyen logika és séma alapján beállított algoritmus mozgatja az adatokat.
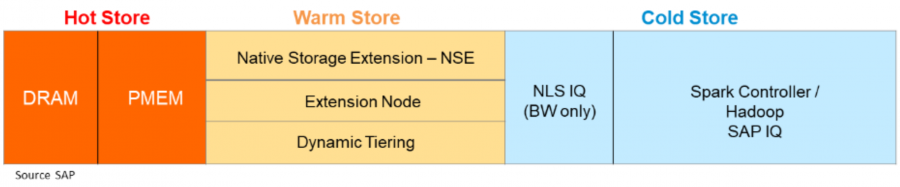
Az SAP erre 3 különböző réteget határozott meg: Hot, Warm, Cold.
Hot: Ezek az adatok a legfontosabbak és legkritikusabbak az üzletmenet szempontjából, így a lehető leggyorsabb elérésű, azaz legalacsonyabb késleltetésű területen kell tárolnunk.
Warm: Ritkábban használt adatok, de még mindig részei az adatbázisnak.
Cold: Ezekre az adatokra csak ritkán van szükség, általában archív, vagy úgynevezett „compliance” céllal kerülnek megőrzésre. Erre a célra olcsóbb és lassabb tárolók is megfelelők.
Melyik Data Tiering megoldást használjuk?
A válasz: attól függ…
Akkor lehet valós teljesítményt és megtakarítást realizálni, ha megfogadjuk a következőt:
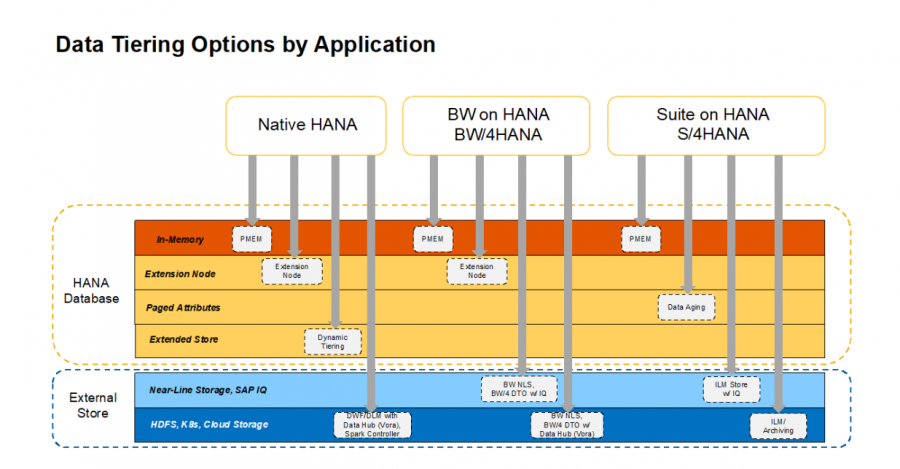
A Data Tiering stratégiát összehangba kell hozni az SAP HANA deployment-tel.
Az adatfeldolgozási rétegnek, a költségeknek és a teljesítménynek meg kell felelniük az alkalmazásprofilnak.
Ehhez további hasznos információk találhatók többek között az SAP blogján: https://blogs.sap.com/2019/03/07/recommended-data-tiering-approaches-for-sap-and-native-applications/
Az SAP által kínált lehetőségek közül kettőt mindenképp kiemelnék – melyekre több gyártónak is van megoldása -, ráadásul ezek SAP Certified tanúsítvánnyal is rendelkeznek.
PMEM – Persistent Memory
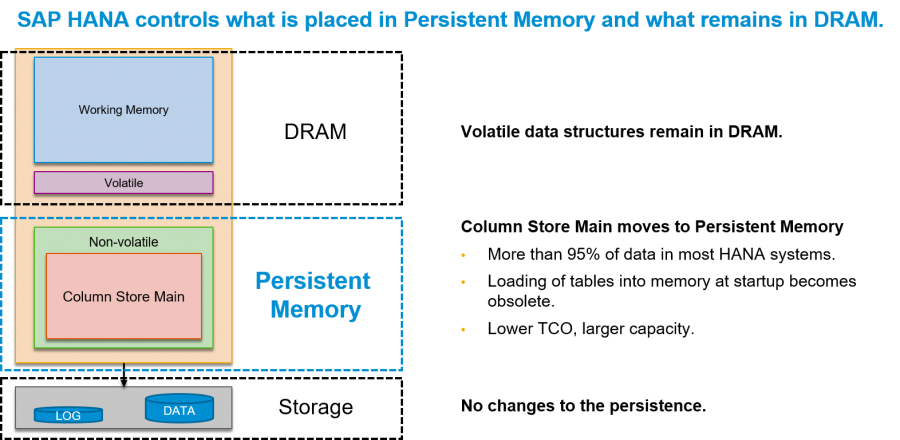
A PMEM alapvetően a DRAM-nál picit lassabb, viszont az SSD rétegnél sokkal gyorsabb ún. „nem felejtő réteget” jelent. Az SAP HANA képes észlelni a perzisztens memória hardverét, és úgy állítja be magát, hogy ezeket az adatstruktúrákat automatikusan a perzisztens memóriára helyezi, míg az összes többit a DRAM-ban tartja. A PMEM-et úgy kell elképzelni, mint a DIMM modulok helyére tehető és byte szinten címezhető terület.
A perzisztens memóriának köszönhetően a szerver újraindulása esetén nem veszti el a benne tárolt adatokat, mert egy pici kapacitás vagy akku biztosítja a DRAM chip-ek tartalmának NAND chip-be írását. Ez azt jelenti, hogy egy tervezett vagy nem tervezett leállás esetén is nagyságrendekkel gyorsabban indulhat el a rendszerünk, hiszen az adatok visszatöltése a perszisztens rétegből történik. Az SAP HANA tudja, mely adatstruktúrák profitálnak leginkább a perzisztens memóriából.
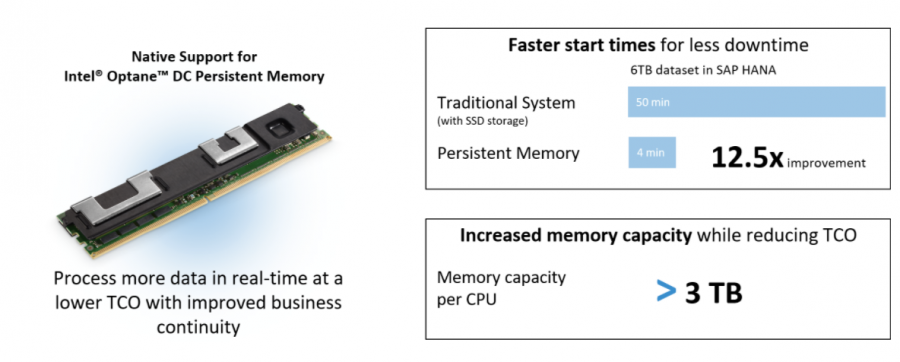
Az orlandói Sapphire rendezvényen az SAP társalapítója és elnöke, Hasso Plattner perzisztens memóriával mutatta be az első számokat az indítási idők javulásáról. Az SAP HANA 6 TB-os példánya alapján az indítási idő – beleértve az adatbetöltést – 12,5-szeresére javult (50 percről normál DRAM-mal mindössze 4 percre) perzisztens memória mellett. Ez lényegesen alacsonyabb időtartamot jelent a tervezett üzleti leállásoknál – például egy frissítés miatt -, csak néhány perc egy óra helyett. Az üzleti leállások hosszának ilyen mértékű csökkentése egyébként csak olyan megoldások alkalmazásával lehetséges, mint az SAP HANA rendszer replikációja.
NSE – Native Storage Extension
Az SAP HANA NSE egy beépített lehetőség a Warm, vagyis a nem túl gyakran használt adatok közvetlenül a tárhelyről történő elérésére. Erre az SSD, vagy NVME alapú tárolók a legmegfelelőbbek.
A technológia alapja, hogy az előre definiált lekérdezések segítségével bizonyos adattáblák, vagy azok egy részét helyezzük át a memóriából a tároló rétegbe. Természetesen a mozgatás szabályrendszerek mentén, automatizáltan történik. Például az 3 évnél régebbi készletezési, vagy szerződésekkel kapcsolatos adatokat helyezzük át. Amennyiben ezekre az adatokra szükségünk van, úgy az SAP HANA egy, a memóriából erre a célra fenntartott Buffer Cache területre kerül visszamozgatásra.
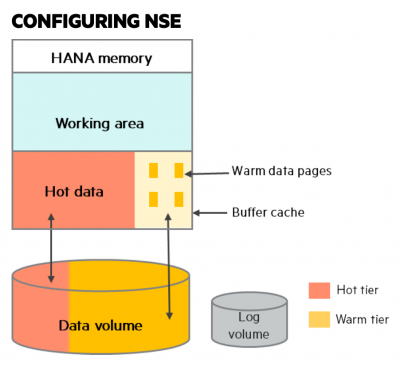
Megtérülés?
Felmerülhet a kérdés, hogy hogyan viszonyul a memóriában lévő adatok és az SAP HANA NSE adatainak aránya a költségekhez és a teljesítményhez.
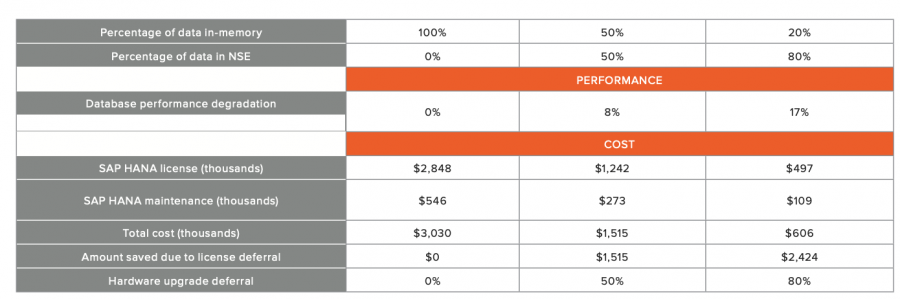
A fenti táblázat segítséget nyújt ennek megértésében. Jól látszik, hogy ahogy csökkentjük a memóriában tárolt adatok mennyiségét, ahhoz képest mennyivel degradálódik a performancia és mennyivel csökkennek a költségek. Fontos megjegyezni, hogy az SAP HANA memória alapján is licencelődik, így minél kevesebb memóriát használunk, annál kevesebb licencre lesz szükségünk, amivel további kiadásokat csökkenthetünk.
Állunk örömmel rendelkezésedre, ha optimalizálni szeretnéd az SAP rendszered!




